
Cost-Centered Active Learning in Video Sequences
Personnel: Ryan Benkert, Yash-Yee Logan, Kiran Kokilepersaud, Chen Zhou, Mohit Prabhushankar
Goal/Motivation: Active learning for efficient video annotation requires a differential approach to active learning. Effective algorithms select low-cost video sequences with high information content.
Challenges: Conventional active learning approaches typically rank data points individually and sample single instances for annotation. Unfortunately, the workflow is unrealistic in active learning on sequential data where labeling is performed on multiple data points at once. In particular, sequential dependencies result in significantly different annotation cost (in e.g. time) for each individual sample. For instance, static labels (e.g. parked cars) can be copied between neighboring video frames without a significant time overhead. As a result, annotation cost and training set size scale in a non-linear fashion (Figurte~1); conventional frameworks assume a linear dependency.
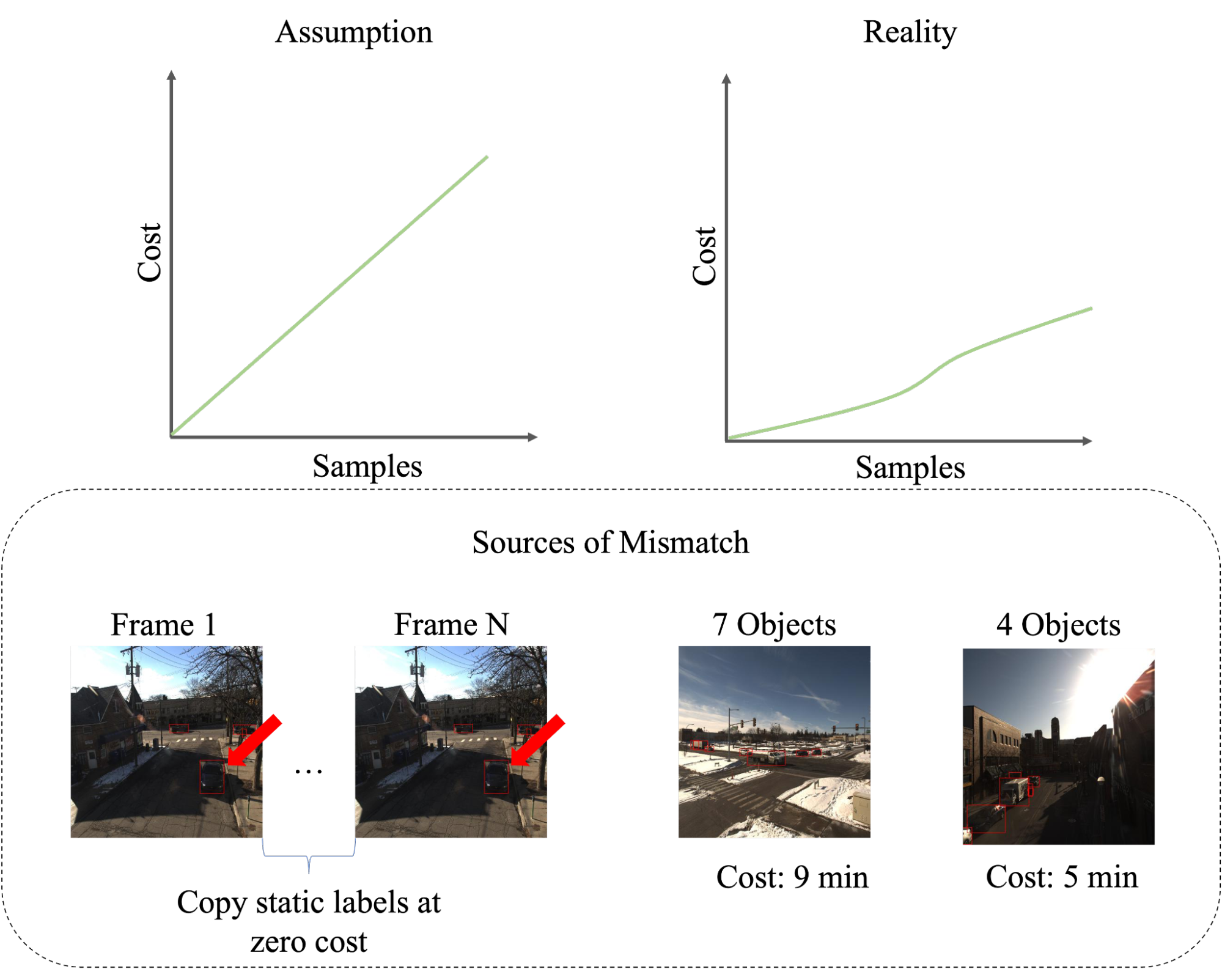
High Level Description of the Work: At OLIVES, we view video active learning from a cost-centered perspective. We present the first active learning dataset FOCAL for sequential cost analysis on video sequences for autonomous driving settings [1]. It consists of a plethora of real-world scenarios that include 149 unique sequences, 109 000 frames, and79 unique scenes across a variety of weather, lighting, and seasonal conditions. In our analysis, we compare popular active learning approaches in singular and sequential setting. For sequential settings, algorithms largely neglect cost information and scale linearly to randomly sampling individual data points; the naïve baseline

References:
R. Benkert, K. Kokilepersaud, C. Zhou, M. Prabhushankar, g. AlRegib, A. Parchami, E. Corona, K. Singh, J. Chakravarty, G. Pandey, “FOCAL: An Annotation-Cost Centered Video Dataset for Active Learning”, AAAI 2022, submitted on August 15th 2022